JavaScript 善用解构赋值
JavaScript 善用解构赋值
场景
在今天写 JavaScript 函数时,发现了一个有趣的技巧。
在此之前,吾辈想知道泥萌需要默认值的时候是如何做的呢?
例如下面的函数 print,吾辈需要在没有给定参数 user 的情况下,给出合适的输出
1 | function print(user) { |
那么,我们应该怎么优化呢?
- 三元表达式
||/&&赋予默认值Object.assign()合并对象
我们分别来实现一下
三元表达式实现
1 | function print(user) { |
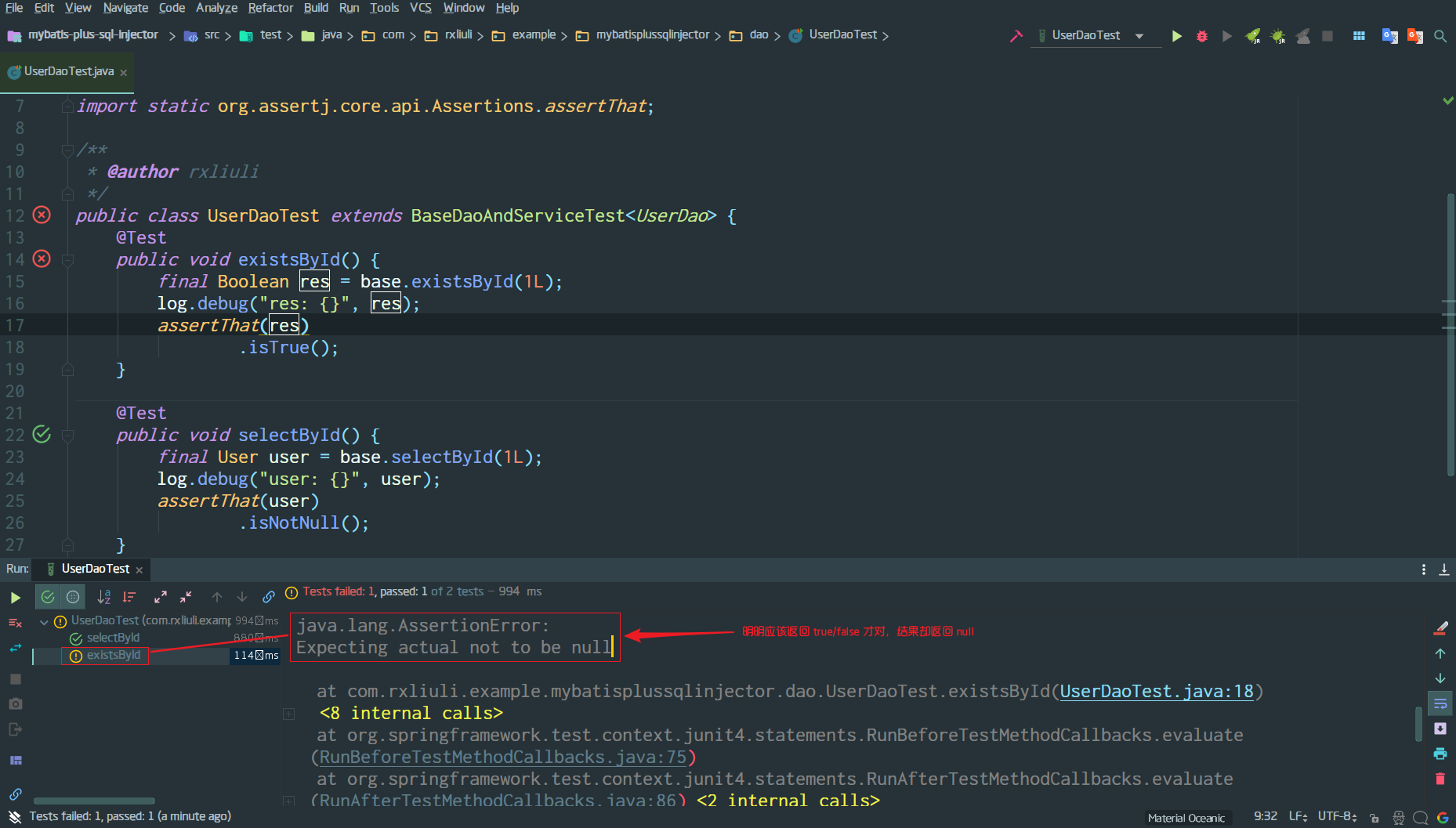
|| / && 赋予默认值
1 | function print(user) { |
使用 && 也可以
1 | function print(user) { |
||/&&解释
||用来取默认值,避免太多的if判断。例如对于a || b我们可以认为:如果a为空,则赋值为b&&用来连续执行,避免深层嵌套的if判断。例如对于a || b,我们可以认为:如果a不为空,则赋值为b注:||
/&&` 非常适合简单的默认值赋值,但一旦设置到深层嵌套默认值就不太合适了
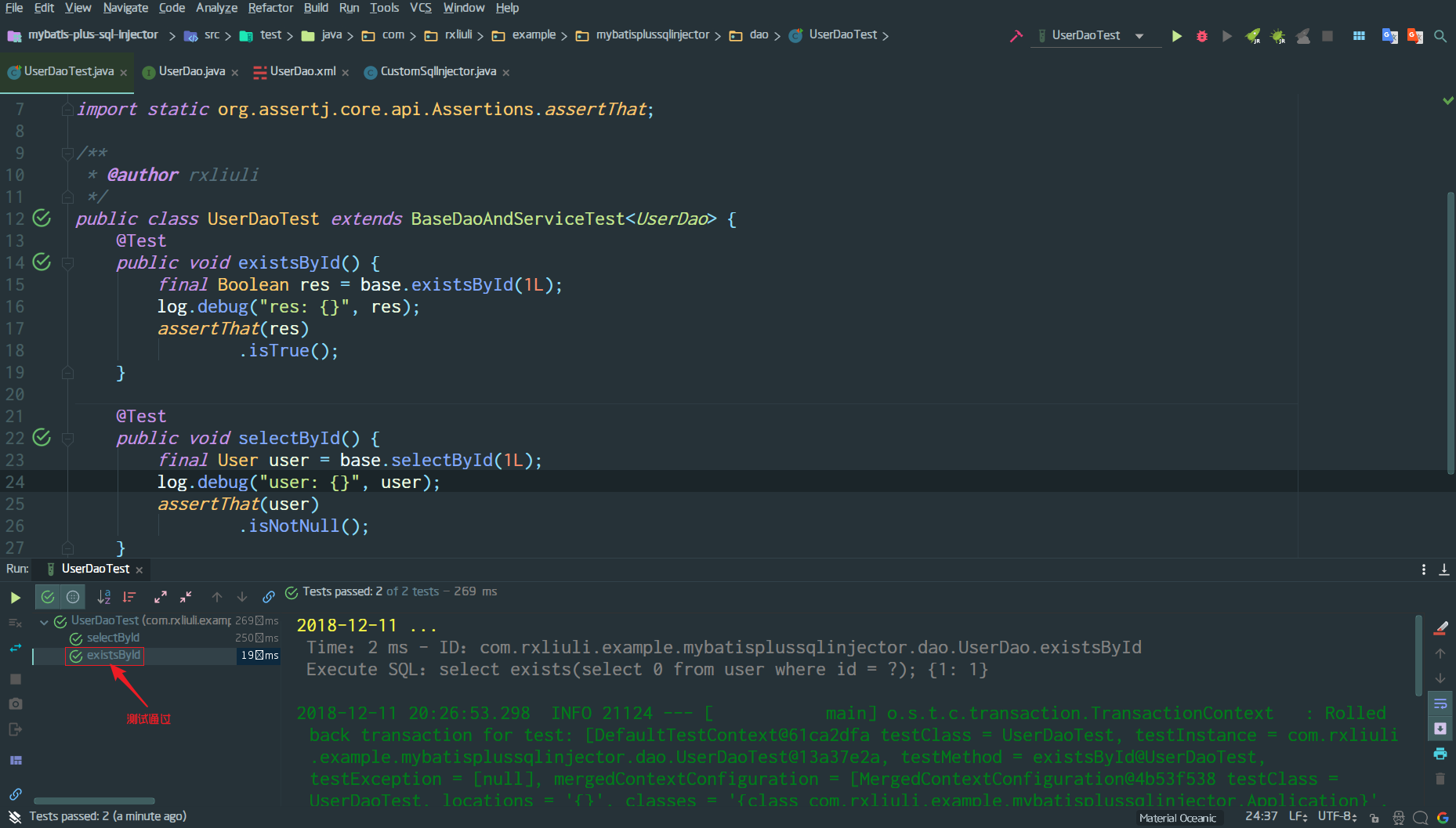
Object.assign() 合并对象
1 | function print(user) { |
可以看出
- 三元表达式的方式方式明显有点繁琐
||/&&很好很强大,缺点是看起来很不直观,而且容易混淆Object.assign()合并对象的方式应该算是最好的了,然而是在方法内部进行的初始化,作为调用者除非查看文档或源码才能知道
那么,有没有更好的解决方案呢?
解构赋值
解构赋值是 ES6 的一个新的语法,具体可以查看 MDN。
下面是一些简单的解构赋值操作
数组解构
1 | var arr = [1, 2, 3, 4] |
对象解构
1 | var user = { |
啊嘞,吾辈好像不知不觉间把解决方案写出来了。。。?
分析
让我们好好看下这段代码
1 | function print({ name = '未设置', age = 0 } = {}) { |
一眼看过去,是不是感觉很直观,如果稍微了解一点 ES6 就能瞬间明白这是解构赋值以及默认参数
我们分析一下具体流程
调用
print函数检查参数是否为有值,没有的话设置默认值
{}
相当于1
2
3if (!user) {
user = {}
}解构参数,检查解构的属性是否有值,没有的话设置默认值
相当于1
2
3
4
5
6
7
8
9
10
11
12var name
if (!user.name) {
name = '未设置'
} else {
name = user.name
}
var age
if (!user.age) {
age = 0
} else {
age = user.age
}进入函数内部
关键就在于第 2,3 步,默认参数 和 解构赋值 都是 ES6 的新特性,善于使用能大大简化代码的繁琐性。
希望有更多的人能够学会怎么使用,让我们早日抛弃 babel 吧 (*^ ▽ ^)/