使用 heroku 免费部署 Shadowsocks
使用 heroku 免费部署 Shadowsocks
场景
现在看到这篇文章的各位是如何翻墙的呢?
- 使用 vultr 自建 SSR
- 购买 SSR/V2ray 服务
- 使用免费的梯子
- 其他?
之前提到过 heroku 可以搭建免费的 SS 服务,这里就来具体说明一下如何操作
附:免费的服务来之不易,请勿滥用 heroku 服务,避免对正常开发者使用造成影响
具体步骤
注册 heroku 账号
在 注册页面 填写一些信息就可以免费注册 heroku 帐号了。
免费账号有如下限制
- 能够使用 512M 内存
- 30min 无人访问后应用休眠
- 应用每个月 500h 的免费活动时间
对于真正的项目这种配置当然不够,但如果只是部署一个 Shaodowsocks 的话还是绰绰有余的,而且也不可能无时无刻都在使用 Shadowsocks。
注:如果想要快速稳定的 SS 服务,请选择购买付费的 SS 服务。毕竟,某种意义上,免费的才是最贵的!
创建一个 Shadowsocks APP
设置 APP
需要设置的有 4 项,其中的密码必填!
- APP 名字,也是之后 heroku 为你分配的子域名,默认为随机字符串
- 选择服务器的位置,默认美国
- 选择 Shadowsocks 连接密码
- 选择加密算法,默认 aes-26-cfb
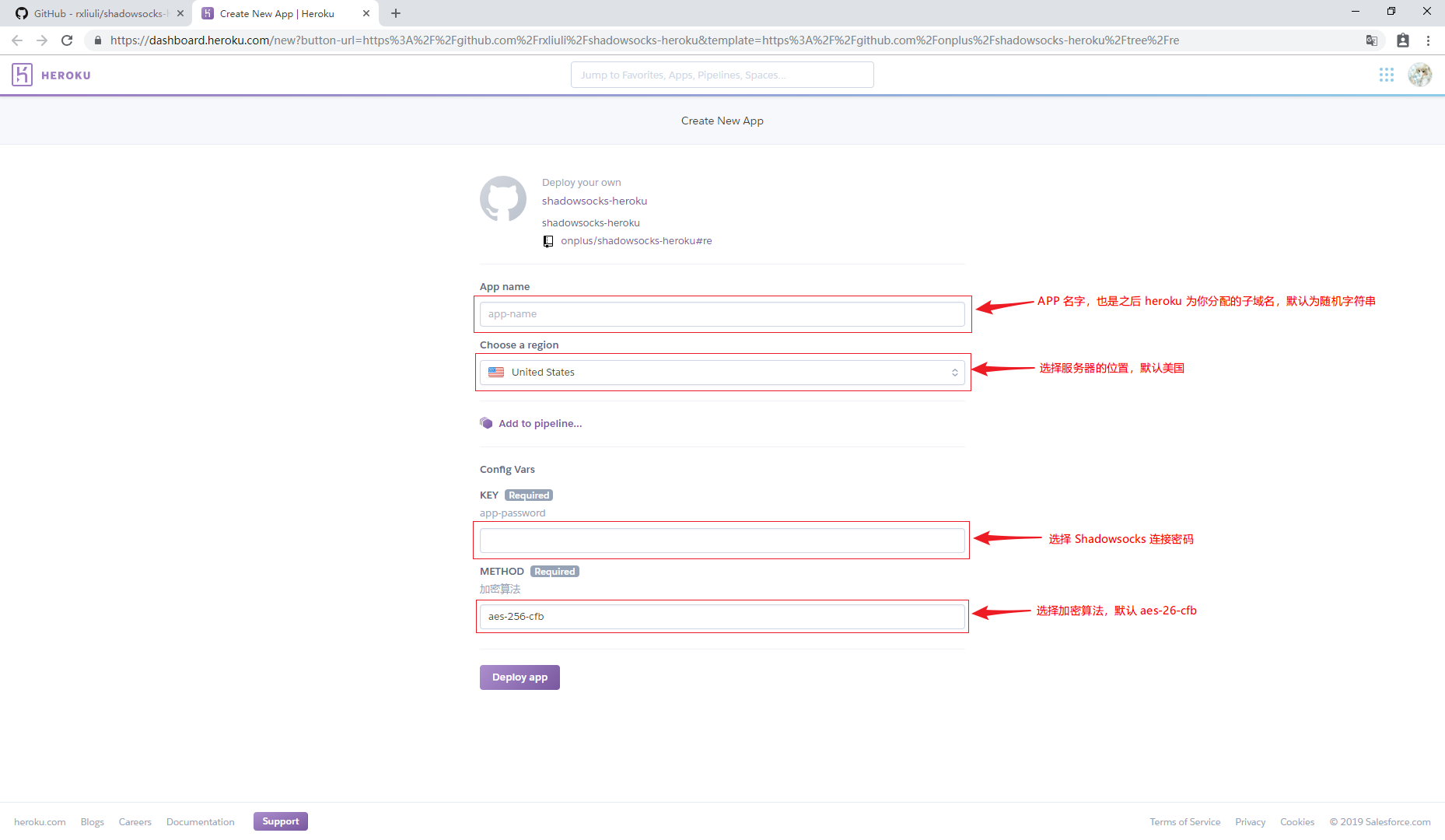
设置完成后点击 Deploy app,等待部署完成后,点击最下方的 View 按钮,如果在新标签页看到下面的这句话就代表部署成功了
1 | Welcome to Heroku https://github.com/onplus/shadowsocks-heroku |
使用客户端
在 Shadowsocks 客户端页面 下载对应平台的客户端,Windows 平台的链接是 https://github.com/onplus/shadowsocks-heroku/releases/download/0.9.10.1/ss-h-win64.zip。

解压出来,可以看到 config.json 文件,我们需要修改一下配置
1 | { |
现在,我们可以双击 ss-h.exe 启动 Shadowsocks,这种方式会打开一个命令行窗口。如果想后台运行可以使用 start.vbs 脚本。
浏览器设置
安装插件 Proxy SwitchyOmega,然后在 导入/导出 > 在线恢复 中输入 https://gist.githubusercontent.com/rxliuli/7447e51653a35e2a36a294f2b8ba9052/raw/57154aaa799f1c9d413500b63f38eb91fd1c075c/SwitchyOmegaBak,然后点击 恢复。
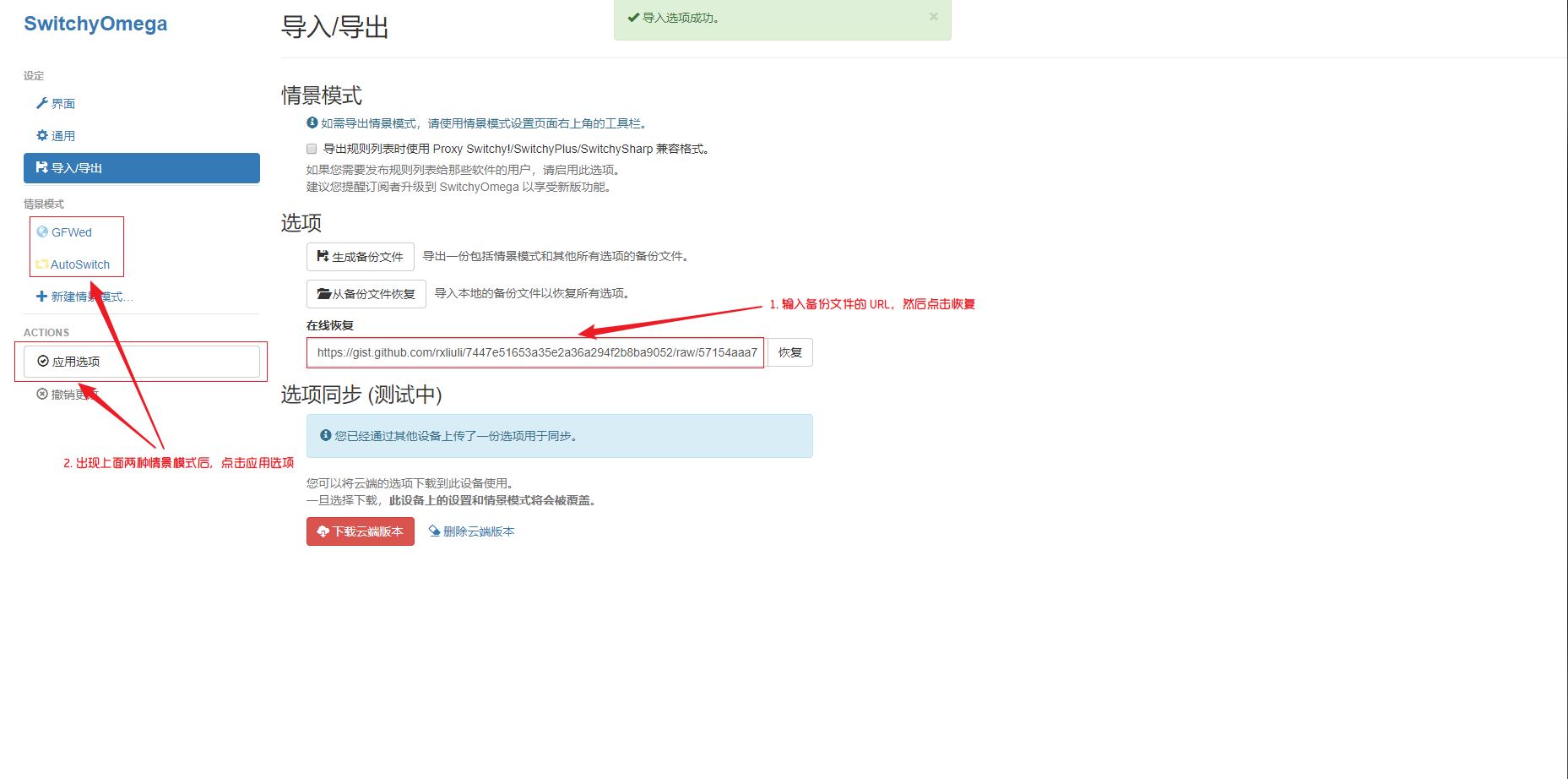
访问 https://www.google.com/,嗯,现在还无法访问,我们选择 AutoSwitch 模式
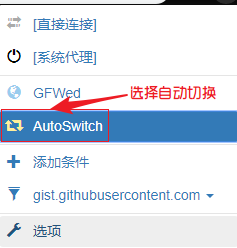
好了,大功告成,我们以后可以正常在浏览器上网了!