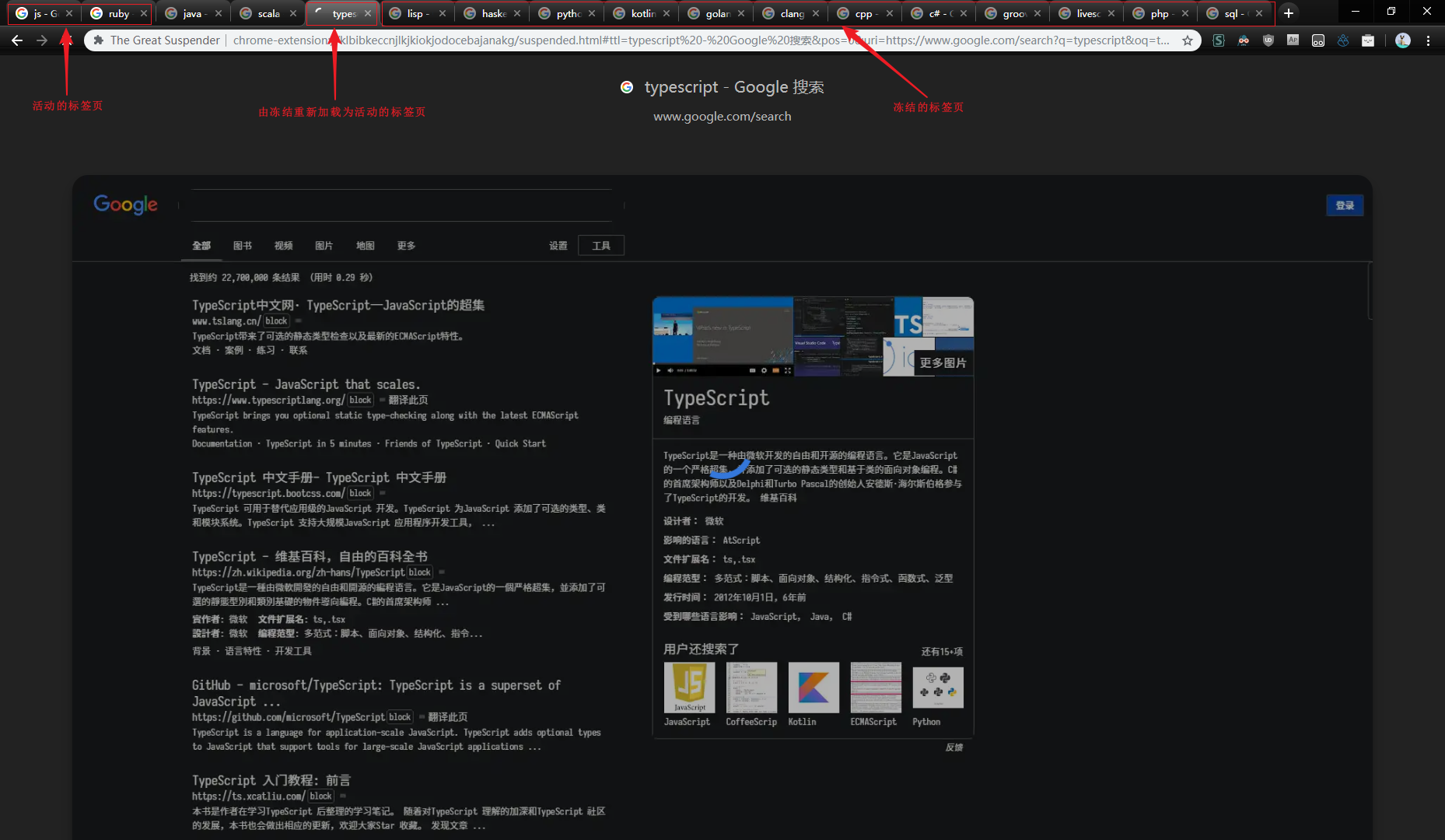
functionwarp(obj) { const result = newProxy(obj, { get(_, k) { const v = Reflect.get(_, k) if (v !== undefined) { return v } return'' }, }) return result }
不能直接代理一些需要 this 的对象 这个问题就比较麻烦了,任何需要 this 的对象,代理之后的行为可能会发生变化。例如 Set 对象
1 2
const proxy = newProxy(newSet([]), {}) proxy.add(1) // Method Set.prototype.add called on incompatible receiver [object Object]
是不是很奇怪,解决方案是把所有的 get 操作属性值为 function 的函数都手动绑定 this
1 2 3 4 5 6 7 8 9 10 11
const proxy = newProxy(newSet([]), { get(_, k) { const v = Reflect.get(_, k) // 遇到 Function 都手动绑定一下 this if (v instanceofFunction) { return v.bind(_) } return v }, }) proxy.add(1)
;(async () => { // 模拟一个异步请求,接受参数并返回它,然后等待指定的时间 asyncfunctionget(ms) { awaitwait(ms) return ms } const fn = mergeMap(get) let last = 0 let sum = 0 awaitPromise.all([ fn(30).then(res => { last = res sum += res }), fn(20).then(res => { last = res sum += res }), fn(10).then(res => { last = res sum += res }), ]) console.log(last) // 实际上确实执行了 3 次,结果也确实为 3 次调用参数之和 console.log(sum) })()
;(async () => { // 模拟一个异步请求,接受参数并返回它,然后等待指定的时间 asyncfunctionget(ms) { awaitwait(ms) return ms } const fn = switchMap(get) let last = 0 let sum = 0 awaitPromise.all([ fn(30).then(res => { last = res sum += res }), fn(20).then(res => { last = res sum += res }), fn(10).then(res => { last = res sum += res }), ]) console.log(last) // 实际上确实执行了 3 次,然而结果并不是 3 次调用参数之和,因为前两次的结果均被抛弃,实际上返回了最后一次发送请求的结果 console.log(sum) })()
;(async () => { // 模拟一个异步请求,接受参数并返回它,然后等待指定的时间 asyncfunctionget(ms) { awaitwait(ms) return ms } const fn = concatMap(get) let last = 0 let sum = 0 awaitPromise.all([ fn(30).then(res => { last = res sum += res }), fn(20).then(res => { last = res sum += res }), fn(10).then(res => { last = res sum += res }), ]) console.log(last) // 实际上确实执行了 3 次,然而结果并不是 3 次调用参数之和,因为前两次的结果均被抛弃,实际上返回了最后一次发送请求的结果 console.log(sum) })()
;(async () => { // 模拟一个异步请求,接受参数并返回它,然后等待指定的时间 asyncfunctionget(ms) { awaitwait(ms) return ms } const time = 100 const fn = asyncTimeout(time, throttle(time, get)) let last = 0 let sum = 0 awaitPromise.all([ fn(30).then(res => { last = res sum += res }), fn(20).then(res => { last = res sum += res }), fn(10).then(res => { last = res sum += res }), ]) // last 结果为 10,和 switchMap 的不同点在于会保留最小间隔期间的第一次,而抛弃掉后面的异步结果,和 switchMap 正好相反! console.log(last) // 实际上确实执行了 3 次,结果也确实为第一次次调用参数的 3 倍 console.log(sum) })()
你是否也曾因为 Chrome 开了太多标签页而占用了庞大的内存?那么 The Great Suspender 就是最好的帮手,它能自动冻结后台一段时间没有访问的标签页,以便于释放系统内存。并且,当你再次访问时,标签页将会自动重新加载。如果你也经常开了很多个标签页忘记关闭了,那么它可以帮助你自动管理他们。
assign<T, U>(target: T, source: U): T & U; assign<T, U, V>(target: T, source1: U, source2: V): T & U & V; assign<T, U, V, W>(target: T, source1: U, source2: V, source3: W): T & U & & W; assign(target: object, ...sources: any[]): any;
按这个实现,多于 4 个参数就直接丢掉类型信息了,建议 ts 至少把 A-Z 都作为泛型量用上…
一些很明显的类型推断却推断不出来
用 assert 方法做参数检查是很常用的做法,一个简单的 assert 方法:
1 2 3
functionassert(condition, msg) { if (condition) thrownewError(msg) }
然后看这样一段代码:
1 2 3 4
functionfoo(p: number | string) { assert(typeof p === 'number', 'p is a number') p.length// 这里报错,ts 竟然不知道到这一步 p 必定是 string 类型 }
functiondebounce(delay, action, init = undefined) { let flag let result = init returnfunction(...args) { if (flag) clearTimeout(flag) flag = setTimeout(() => { result = action.apply(this, args) }, delay) return result } }